Building a Self-Correcting PDF Extraction Engine
Investment portfolio PDFs are one of those problems that looks solved until you’re the one holding the data. Every bank uses a different layout, numbers show up in US format (1,234.56), European format (1.234,56), or Swiss format with apostrophes (1'234.56), and tables span multiple pages where headers shift between document versions. A field that lives in column 3 on one bank’s report is in column 7 on another’s.
The traditional approach is to write a parser per format and maintain it forever, which doesn’t scale past a handful of banks. The alternative is to hand the PDF to an LLM and ask for structured JSON, which works well enough on the first document but silently fails on the tenth when it encounters a layout it hasn’t seen before. I needed something in between — AI-driven flexibility for handling new formats, with deterministic guardrails for knowing when the output is wrong.
Why extraction was never the hard part
A portfolio report with 60 holdings has hundreds of numeric fields, and a human reviewer has no realistic way to verify them. If the system extracts 847 numbers and three of them are wrong, nobody’s catching that by reading the output. The wrong number will flow into a spreadsheet, inform a decision, and nobody will trace the error back to the extraction step because the other 844 numbers were fine.
So the architecture isn’t organized around how to get data out of PDFs — it’s organized around how to know the data I got out is correct. Extraction is one step, and validation is everything that follows it.
Two paths through the system
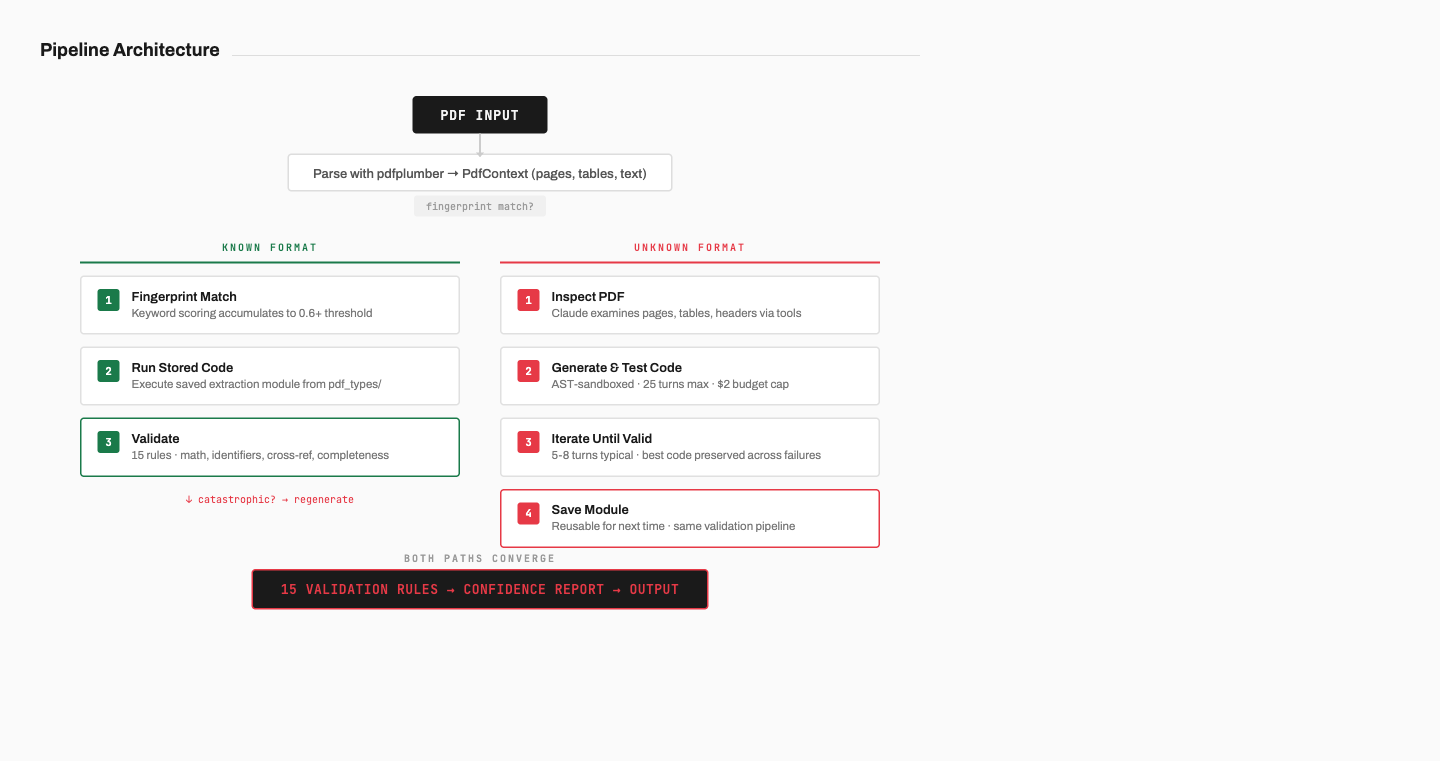
The pipeline has two modes depending on whether it’s seen a PDF format before. Known formats get matched by fingerprinting and processed with stored extraction code. Unknown formats trigger an agentic loop where Claude inspects the PDF, writes extraction code, tests it, iterates, and saves a reusable module for next time.
Both paths feed into the same validation pipeline, which matters because a previously-working format can break. If a bank updates their template and the stored code suddenly extracts zero holdings, the system doesn’t return empty results — it flags the extraction as catastrophic and falls back to regeneration automatically.
Fingerprinting: how the system recognizes documents
Each known PDF format lives as a standalone Python module in a pdf_types/ directory, and every module exports a fingerprint() function that scores how likely a given PDF matches that format by checking for bank-specific keywords and document type indicators.
def fingerprint(ctx: PdfContext) -> float:
text = ctx.all_text()
score = 0.0
if "ING Bank N.V. Amsterdam" in text:
score += 0.3
if "Extras de cont" in text:
score += 0.2
if "INGBROBU" in text:
score += 0.2
if re.search(r"Data tranzactiei", text):
score += 0.15
return min(score, 1.0)No single keyword is enough to commit — scores accumulate from multiple weak signals, and the match threshold defaults to 0.6, meaning two or three strong markers need to agree before the system picks a format. This prevents false matches when two banks share similar terminology.
At startup, a TypeRegistry scans the directory and loads every module dynamically via importlib, so adding support for a new bank means dropping a .py file in a folder with no config files, no registration code, and no restart required.
The agentic loop: writing extraction code for new formats
When no fingerprint matches, the system hands the PDF to Claude and gives it three tools.
The first is inspect_pdf, which lets Claude examine any page’s text content, table structures, headers, and row data. This is how it understands the document layout without needing the raw PDF bytes in context, which matters because large PDFs would eat through the token budget.
The second is run_extraction, where Claude writes Python code and submits it for execution. The code goes through an AST validator first, executes inside a restricted namespace with no builtins access, and the tool returns a quality report showing which fields were extracted, which are missing, and whether the math checks pass. If the code is valid, the toolkit saves it as the best attempt so far, which means a failed iteration doesn’t overwrite a working one.
The third is get_extraction_json, which returns the full JSON output of the last successful extraction so Claude can verify specific values against what it saw in the PDF. This is how it catches errors like a price that got parsed as a date or a negative sign that was dropped.
class AgenticGenerator:
def __init__(
self,
types_dir: str | Path,
*,
model: str = "claude-sonnet-4-6",
max_turns: int = 25,
max_budget_usd: float = 2.0,
)The loop caps at 25 turns and $2 in API costs, and Claude typically converges in 5-8 turns — inspect the structure, write a first attempt, check the output, fix edge cases, verify the numbers. If the budget runs out, the system exits gracefully with the best code produced so far. Every API call updates a running cost total based on token counts and model pricing, so the cap is enforced per-token rather than per-turn.
Code safety through AST validation
Every piece of generated code passes through an AST validator before it runs, and the validator is strict about what it allows.
The import whitelist covers decimal, datetime, re, math, collections, itertools, and the project’s own models. Everything else is blocked — no os, sys, subprocess, socket, pathlib, pickle. Operations like exec, eval, compile, open, __import__, and getattr are forbidden by name, and every module must export PDF_TYPE_ID, BANK_NAME, fingerprint(), and extract().
If the validator finds violations, the code never executes and Claude gets the error list to fix in the next iteration. In practice, violations are rare after the first turn because the system prompt documents the sandbox constraints upfront.
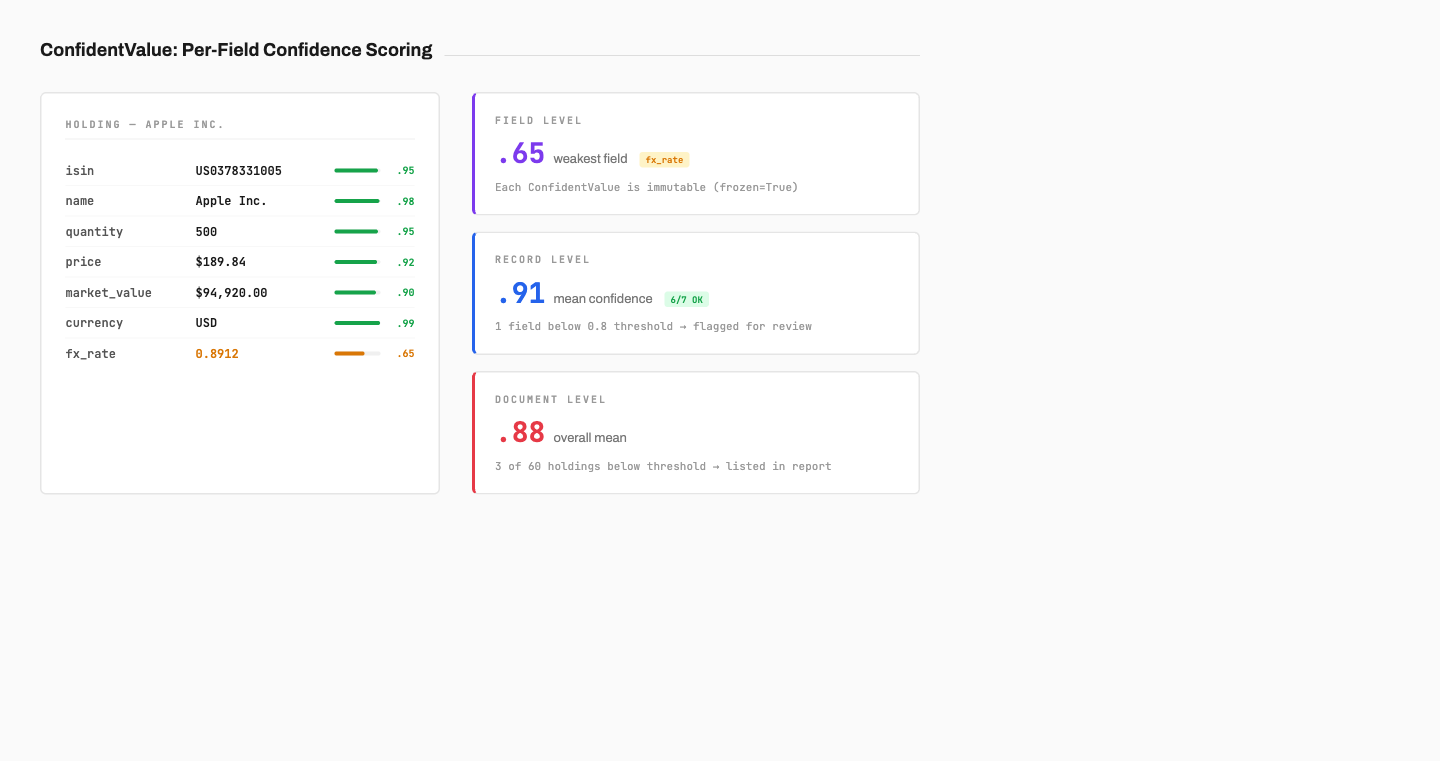
Per-field confidence scoring
The core data abstraction is ConfidentValue[T], a generic wrapper that pairs any extracted value with a confidence score and an optional source location recording which page, table, row, and column it came from.
class ConfidentValue(BaseModel, Generic[T], frozen=True):
value: T
confidence: float = Field(ge=0.0, le=1.0, default=1.0)
source: SourceLocation | None = NoneEvery field on every model uses this wrapper — a holding’s ISIN, its quantity, its price, and its market value are all ConfidentValue instances with individual scores.
class Holding(ExtractedRecord):
isin: ConfidentStr | None = None
name: ConfidentStr | None = None
quantity: ConfidentDecimal | None = None
price: ConfidentDecimal | None = None
market_value: ConfidentDecimal | None = None
currency: ConfidentStr | None = None
fx_rate: ConfidentDecimal | None = NoneThe frozen=True is deliberate. If any part of the pipeline could silently change a confidence score, the entire scoring system becomes unreliable because you’d end up with confidence numbers that don’t reflect what actually happened during extraction. Making the wrapper immutable means that once a value is extracted with 0.85 confidence, that 0.85 follows it through validation, aggregation, and reporting without any opportunity to desynchronize.
The system aggregates confidence at three levels: per field where each ConfidentValue has its own score, per record where it computes min, mean, and a list of low-confidence fields for each holding or transaction, and per document where it calculates overall mean and min across all records along with a list of records below threshold. When the system says “this document’s weakest point is the FX rate on holding 14 at 0.6 confidence,” that’s specific enough for a reviewer to act on without re-checking every number.
The validation rule engine
Every extraction result, whether from stored code or freshly generated, passes through a rule engine with 15 validation rules organized into six categories. The rules are deterministic — they don’t ask an LLM whether the output looks correct, they check whether the numbers are internally consistent, and that’s why they work.
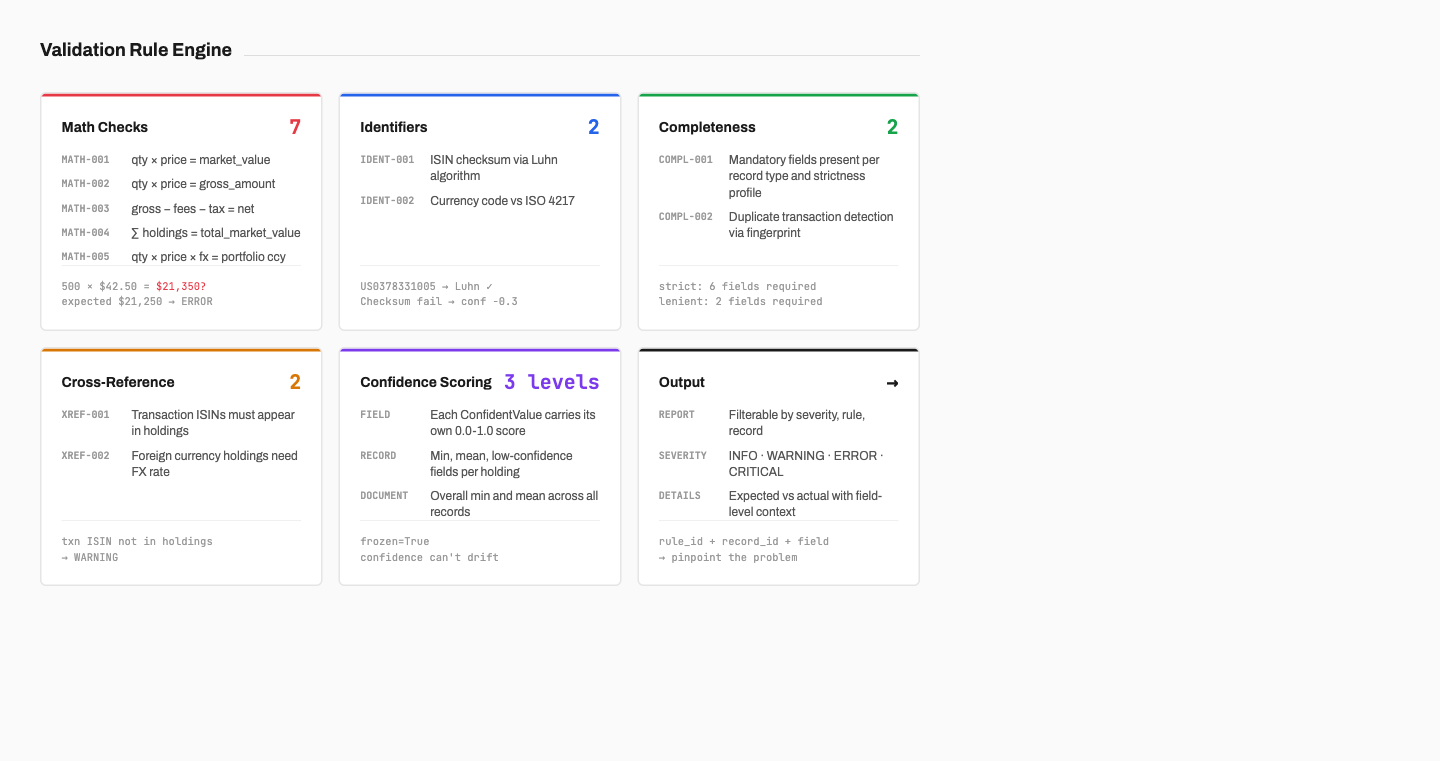
Math checks
Seven rules cross-check the document’s own numbers against themselves. Quantity times price should equal market value on every holding, quantity times price should equal gross amount on every transaction, and gross minus fees minus tax should equal net amount. The sum of all holding market values should equal the portfolio total. If any of these don’t add up within the configured tolerance, the rule flags exactly which record and which field failed and what the expected value should have been.
for h in data.holdings:
if h.quantity is None or h.price is None or h.market_value is None:
continue
expected = h.quantity.value * h.price.value
actual = h.market_value.value
if not _close_enough(expected, actual, tolerance):
issues.append(ValidationIssue(
rule_id="MATH-001",
severity=Severity.ERROR,
message=f"qty * price != market_value: {expected} != {actual}",
record_id=h.record_id,
field_name="market_value",
expected=str(expected),
actual=str(actual),
))The default tolerance is 0.001, but FX calculations get a wider 0.01 because exchange rates introduce rounding, and asset allocation weights are checked against a sum of 100% with their own tolerance. All of these are configurable per rule and per bank.
Identifier validation
ISIN checksums get validated with the Luhn algorithm — convert the letters to numbers, double every second digit from the right, subtract 9 if the result exceeds 9, and check that the total is divisible by 10. Currency codes are checked against a set of 33 ISO 4217 currencies.
The ISIN validation does something I’m particularly happy with. Rather than rejecting a value that fails the checksum, it reduces confidence by 0.3. An ISIN like US0378331005 that passes Luhn gets full confidence, while one that matches the 12-character format but fails the checksum is still extracted and just flagged as low-confidence for human review. This prevents a single OCR artifact from discarding an otherwise valid record.
Completeness and cross-reference
Two rules check that mandatory fields are present on every record, where what counts as “mandatory” depends on the strictness profile. A duplicate detection rule fingerprints transactions on trade date, ISIN, gross amount, and transaction type to catch double-counted entries.
Two cross-reference rules check relationships between entities — every ISIN in a transaction should appear in the holdings list, and if a holding’s currency differs from the portfolio currency, there should be an FX rate to explain the conversion. These are warnings rather than errors because there are legitimate edge cases, but they catch a surprising number of extraction bugs in practice.
Execution order
Rules execute by scope: per-holding first, then per-transaction, then per-summary, then cross-entity. This ordering is intentional because cross-entity rules like “do all holdings sum to the portfolio total” depend on entity-level rules having already flagged individual problems — if holding 14 has a wrong market value, the per-holding math check catches that before the cross-entity sum check amplifies it into a second issue.
Each rule queries the ValidationContext for its tolerance, severity, and enabled state, and nothing is hardcoded in the rule itself. The same rule code works across all strictness profiles without modification.
Strictness profiles
Three built-in profiles control how aggressively the system validates. Strict mode requires six mandatory fields on every holding, uses 0.001 tolerance, and flags anything below 0.9 confidence. Standard requires five fields with 0.01 tolerance and 0.8 confidence. Lenient only needs name and market value, tolerates 0.05 discrepancies, and accepts 0.6 confidence.
Profiles can be customized per bank on top of the base settings — a well-structured Swiss bank report might run in strict mode while a messy legacy format from a smaller institution might use lenient with specific rule overrides that suppress known false positives. Severity overrides cascade so that bank-specific settings take precedence over global, which take precedence over the profile default.
Handling number formats across regions
Financial PDFs from different countries format numbers differently, and pushing that complexity into generated extraction code would be a mistake because every new module would need to re-solve the same parsing problems. Instead, the system provides helper functions that the generated code calls.
parse_decimal handles US, European, and Swiss formats along with parenthesized negatives and currency prefixes or suffixes. parse_date tries 13 common date formats from 15.01.2024 to Jan 15, 2024 to 2024-01-15. parse_isin validates format and checksum and returns reduced confidence on checksum failure rather than rejecting the value.
These helpers mean that Claude’s generated code calls parse_decimal(cell_text) without needing to figure out which country’s number format the PDF uses, and the regionalization complexity lives in one place where it’s tested independently of the extraction logic.
Why I made these choices
I chose per-field confidence over per-document confidence because a single score for a whole document is almost useless — if the system says “85% confident,” you don’t know whether every field is around 85% or most fields are at 99% and one is at 10%. Per-field confidence tells you exactly which values need human review and which are safe to trust.
I chose deterministic validation over AI validation because it would be tempting to ask Claude whether the extraction looks correct, but if the extracted data says quantity times price equals 5,001 and the actual market value is 5,000, Claude might say “close enough.” The rule engine says it’s a 1-unit discrepancy with 0.001 tolerance, and that’s an error. I use the AI where it’s strong — understanding document structure and writing extraction logic — and use deterministic checks where they’re strong, which is arithmetic and format validation.
I chose to generate code rather than data because the agentic loop producing Python extraction code means the output is reusable the next time the same format appears, inspectable by a human who wants to understand the logic, testable against the same validation pipeline as stored modules, and gated by the AST validator which blocks dangerous imports and names before the code ever runs. A generated module becomes a permanent asset rather than a one-time result.
I made every ConfidentValue and every ValidationIssue immutable because this prevents the class of bugs where an intermediate pipeline stage accidentally mutates a value or its metadata. If confidence is 0.85 at extraction time, it’s 0.85 at reporting time, and there’s no way for a downstream stage to quietly change that.
What the system catches
In practice, the validation pipeline flags issues that would silently corrupt downstream analysis — rounding errors in market values where the extracted number is off by a few cents, invalid ISIN checksums caused by OCR artifacts, missing FX rates on foreign-currency holdings that would produce wrong portfolio-level totals, duplicate transactions that would inflate trade volumes, and fields extracted with low confidence that look plausible but came from ambiguous table structures.
For known formats, fingerprinting and stored code produce validated results in under a second. For new formats, the agentic loop typically converges in 5-8 iterations within the $2 budget cap and saves a reusable module. The validation pipeline itself takes milliseconds.
The architecture is extensible in every direction — new PDF formats are added by dropping a file in a directory, new validation rules by implementing a protocol and registering them, and new strictness profiles by setting field requirements and tolerances. None of these extensions require changes to the core pipeline.
Tech stack
| Layer | Stack |
|---|---|
| Core | Python 3.11+, Pydantic 2.0 |
| PDF Parsing | pdfplumber |
| AI | Claude API (Anthropic SDK), agentic tool_use loop |
| Validation | Custom rule engine (15 rules, 6 categories) |
| Models | Generic ConfidentValue[T] with source tracking |
| Code Safety | AST-based code validator (import whitelist, forbidden-name checks) |
| Config | Strictness profiles (strict/standard/lenient) + per-bank overrides |
| Tests | pytest (310+ tests), ruff, mypy |
| Infrastructure | Docker Compose, Prometheus, Grafana |
Building the validation layer took longer than building the extraction, and it’s the part that actually matters when someone is making financial decisions based on the output. The gap between “AI can extract this data” and “I trust this data in production” is the 15 rules, the per-field confidence scores, and the willingness to flag a value rather than silently pass it through.
Newsletter
Email updates
I write about building production AI systems with verifiable output through software engineering practices. One email when I publish, nothing else.
Thank you — you'll hear from me when the next post goes up.
Something went wrong. Please try again or email contact@bogdan-ivanov.ro directly.