Services
AI Pipeline Development
End-to-end systems where AI does extraction, classification, or decision-making inside a deterministic pipeline. From ingestion to structured output — built to fail safely and recover without manual intervention.
Architecture Review
Evaluating existing AI implementations for production readiness. Where is the AI doing too much? Where is deterministic code missing? Where are the failure modes unhandled? You get a written assessment with specific fixes.
Integration & Automation
Connecting disparate systems with real-time data flows. WebSocket streams, REST APIs, webhooks, SMS, email — glued together with intelligent logic at the decision points.
Architecture Review
Finding where the boundaries are wrong before your users do
Most AI systems start as proofs of concept that work well enough in demos, and then someone runs them in production and discovers the failure modes nobody planned for. Extraction that was 94% accurate in testing silently corrupts the other 6% of records downstream. A classification model returns confident predictions for inputs it has never seen, and you don't find out the answer was wrong until a user complains. An API integration works fine until the third-party service changes its response format and the entire pipeline quietly stops processing anything new.
AI is good at judgment calls — extracting meaning from unstructured input, classifying intent, detecting patterns — and it is not good at knowing when it is wrong. That is what deterministic code is for, and it is where most production AI systems have their boundaries in the wrong place.
I review production AI systems to find where the model is doing work that validation logic should be doing, where validation logic is missing entirely, and where failure modes are unhandled because nobody documented what "failure" looks like. You get a written assessment with specific fixes.
What gets reviewed
Pipeline architecture. Where does data come in, what transforms it, and what happens if a transformation fails halfway through? Most pipelines assume success. Input arrives, the model processes it, output gets stored, and the failure path is an exception handler that logs something and moves on. That works until the error is systematic — a schema change, a rate limit, a model returning structured output in the wrong shape — and by then the damage is measured in hours of missing data. I map the actual flow end to end and identify where failures can occur and whether the system can recover without manual intervention.
AI boundaries. Is the model making a judgment call, or is it doing something deterministic code should handle? Models should not be reformatting dates, checking whether required fields are present, or enforcing business rules, because those are deterministic operations with known inputs and known outputs, and putting a probabilistic component in front of them just adds failure modes. I document what the model is doing now and what should move into regular code.
Failure modes. What happens when the API returns an unexpected format, when the model produces invalid JSON, or when the external service is down? Most systems don't have a clear answer. They log something, maybe retry, maybe skip the record, but they don't know which failures lose data, which recover automatically, and which need a human. I list every failure point and whether it is handled, and you see which ones are silent, which ones are catastrophic, and which ones need monitoring.
Observability. Can you see what the system is doing right now, how many requests are in the queue, how long AI calls are taking, and whether something is failing repeatedly? Logs are not observability — logs tell you what happened after it's over, and observability tells you what's happening while the system is running. I check whether the system exposes metrics for throughput, latency, error rate, and queue depth, and whether anyone is actually watching them.
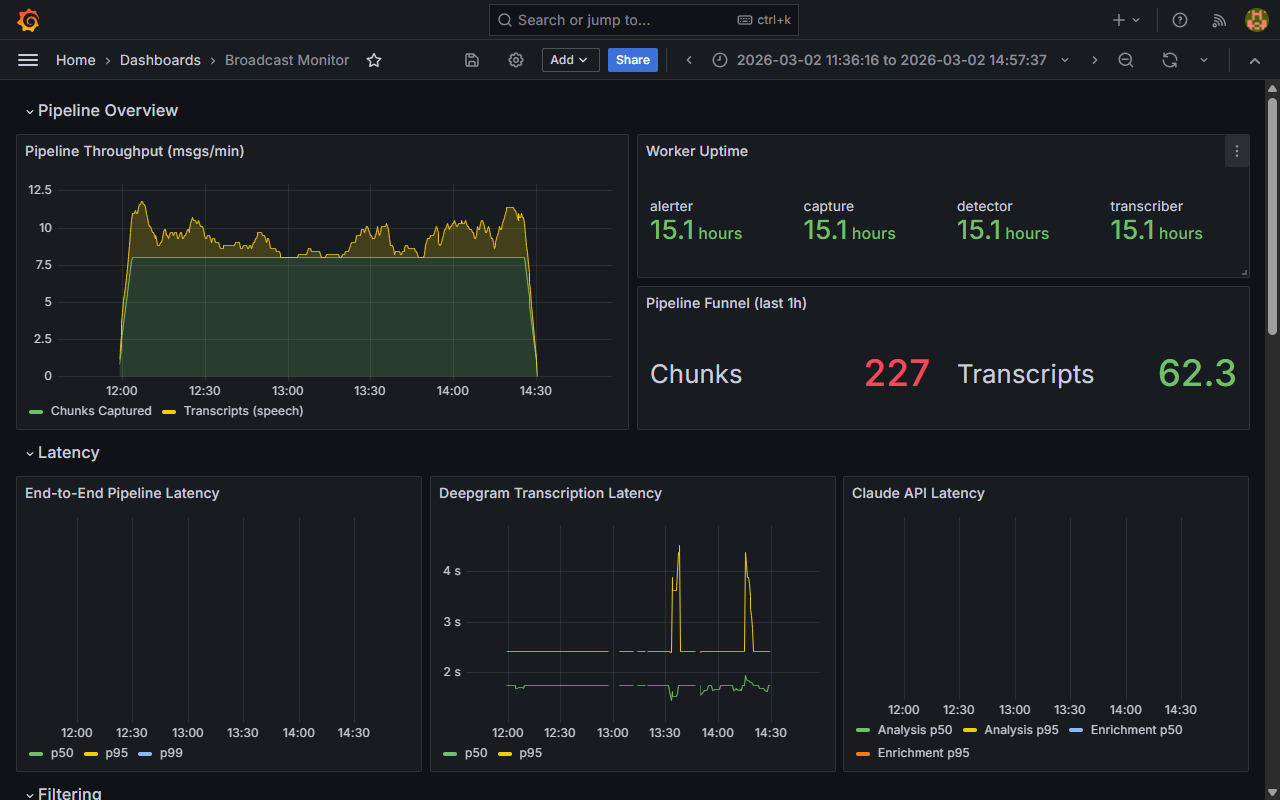
Deployment and recovery. How does the system start, how does it stop, and what happens if it crashes mid-processing? A system that can't restart cleanly isn't production-ready. If a deploy means manually checking which records were half-processed and rerunning them, that is a failure mode the architecture built in on purpose. I verify that queues persist across restarts, that workers can restart without dropping messages, and that there's a way to replay failed jobs without reprocessing everything.
How the review works
1. You send documentation and access. The code repository, architecture diagrams if you have them, access to a running instance in staging or production, and access to monitoring dashboards if they exist. If you don't have diagrams or dashboards that's fine — their absence is part of what I document.
2. I map the system. I trace the pipeline end to end: input sources, where the model is called, what happens to the output, where data is stored, and what happens when something fails. I read the code, check the deployed infrastructure, and watch the logs and metrics to see how the system actually behaves, not how it is supposed to.
3. You get a written assessment. The deliverable is a markdown document with a pipeline flow diagram, AI boundary analysis, a failure mode inventory, observability gaps, deployment and recovery issues, and a prioritized list of fixes ordered by risk. Each fix includes what is broken, why it matters, and what the code change looks like — if the fix is "add retry logic with exponential backoff" you get example code showing where it goes.
4. Implementation support, if you want it. The assessment tells you what to fix, and if you want help fixing it we scope a follow-on engagement with fixed scope, clear deliverable, and defined timeline. I don't do open-ended advisory work. I build the fix or I don't, and if I build it you get working code with tests.
When this makes sense
You are running an AI system in production and you are not confident it handles failures correctly. You know the happy path works, and you don't know what happens when the model returns garbage, the API goes down, or the input format changes.
You built a prototype that worked in testing and now you need to deploy it somewhere it can't fail silently, and you want someone to tell you what breaks before your users do.
You inherited a system and need to understand what it is actually doing before modifying it. The original developer is gone, the documentation is incomplete, and the system works but nobody knows how.
You are about to scale a pipeline and you want to know whether the architecture will hold. It processes 100 requests a day now, it needs to process 10,000, and you need to know where the bottlenecks are and what breaks first.
What this doesn't cover
I don't review machine learning model performance — if you need someone to evaluate accuracy, precision, recall, or whether you should be using a different model architecture, that is a different kind of review. I don't do compliance audits for SOC 2, HIPAA, or GDPR. I don't write new features: the review identifies what is broken and what needs to change, and building the changes is a separate engagement. And I don't do long-term embedded advisory relationships — I review the system, write the assessment, optionally implement the fixes, and then I am done.
Examples from past reviews
Pipeline processing unstructured documents. A system used Claude to extract fields from uploaded PDFs and worked fine in testing, then failed in production when users uploaded scanned images instead of text-based PDFs. The model would return empty results, the system would store an empty record, and nobody noticed until users complained. The fix was to add deterministic OCR preprocessing before the extraction step: if the PDF is an image, run it through Tesseract first, and if Tesseract produces nothing, reject the upload with a clear error instead of silently processing garbage.
Incident detection on audio streams. A system transcribed emergency scanner audio and used keyword matching to flag incidents, which worked at around 60% accuracy because "fire" shows up in plenty of non-emergency contexts. The fix was to keep the keyword matching as a cheap first pass and then hand the full transcript to Claude as a second pass that confirms whether it is a real dispatch based on surrounding context. Accuracy went from 60% to over 90% without touching the transcription or keyword logic.
Third-party API integration. A system polled an external API every 15 minutes to fetch new records and worked fine until the API changed its response format. The system kept running, logged errors for every request, and didn't process any new data for three days before anyone noticed. The fix was schema validation immediately after the response: if the shape doesn't match expectations, halt processing and page someone, rather than logging errors into the void on a critical data path.
Job queue with no acknowledgment. A system used Redis for task queues where workers would pull a job, process it, and mark it done, and if a worker crashed mid-job the job was simply lost with no retry, no recovery, and no alert. The fix was switching to a queue system with acknowledgment semantics so jobs stay in the queue until they are explicitly completed, and if a worker crashes the job goes back in the queue automatically.
How to start
Email contact@bogdan-ivanov.ro with a link to the repository or a short description of what the system does. I'll confirm whether a review makes sense and send back a scope document.