Moving AI from prototype to production
The AI prototype works in the demo. The stakeholders are convinced, the budget is signed, and then the question nobody asked out loud during the demo becomes the only question that matters: what does this system do at three in the morning when nobody is watching?
I’ve been building production systems for seventeen years and production AI systems for the last several, across Romania and elsewhere, and the gap between a working prototype and a system that runs unsupervised is almost always the same set of problems in the same order. This post is the readiness checklist I actually use, followed by the troubleshooting patterns for the failures that show up most often.
Where AI stops and deterministic code starts
The first failure mode of a prototype is that AI is doing everything — parsing the input, deciding what to extract, formatting the output, and sometimes even making the retry decision when something goes wrong. Production requires a harder line. AI handles classification, extraction, and judgment calls, and deterministic code handles validation, retry logic, queueing, formatting, and delivery. Input validation has to happen before the model sees data, output validation has to happen after the model returns data, and the structured output format has to be enforced through tool_use, function calling, or a JSON schema constraint so the model cannot drift. Template rendering, file generation, and data formatting belong outside the model call, because a probabilistic component in front of a deterministic operation is a failure mode you built in on purpose.
In SMS-to-PDF, for example, Claude extracts fields as structured JSON and that is all it does. A separate validator checks required fields, a separate renderer fills the Word template, and a separate emailer delivers the PDF. The model never sees the template file and never controls whether the email gets sent, which means none of those pieces can fail in a way that requires asking the model to try again.
Every failure has to have a recovery path
Prototypes halt on errors and wait for someone to notice. Production systems document every failure scenario upfront and have a recovery path that does not require restarting the service or manually replaying requests. An LLM API timeout retries with exponential backoff and then fails the request with a logged error. A malformed JSON response gets its raw text logged and retries once with a clarified prompt before it gives up. A missing required field rejects the request with specific feedback about what was missing, so the caller can actually fix the problem. A downstream service being unavailable queues the request for retry rather than blocking the pipeline, a rate limit pauses new work and retries queued work after a delay, and capacity being exceeded rejects new work with a 503 rather than growing an unbounded queue.
FirstOnScene processes audio chunks every fifteen seconds, and if Deepgram times out, that chunk is logged and skipped because the next chunk is already arriving. If Claude returns invalid JSON, the raw response is logged and the incident is marked as unparsable. The pipeline does not stop.
You cannot run what you cannot see
Prototypes are debugged by running a test request and staring at print statements. That does not scale, and more importantly it does not work at 3 AM when nobody is watching. Production requires metrics: request volume, error counts, success rate, LLM API latency at p50/p95/p99, queue depth, and processing lag, all visible in real time. Logs have to carry a request ID, a timestamp, an input hash, an output hash, and an error type so that when something goes wrong a week later you can actually trace it. Alerts have to fire when the error rate exceeds a threshold or the queue depth grows unbounded, and you have to be able to answer “how many requests failed in the last hour” without grepping log files.
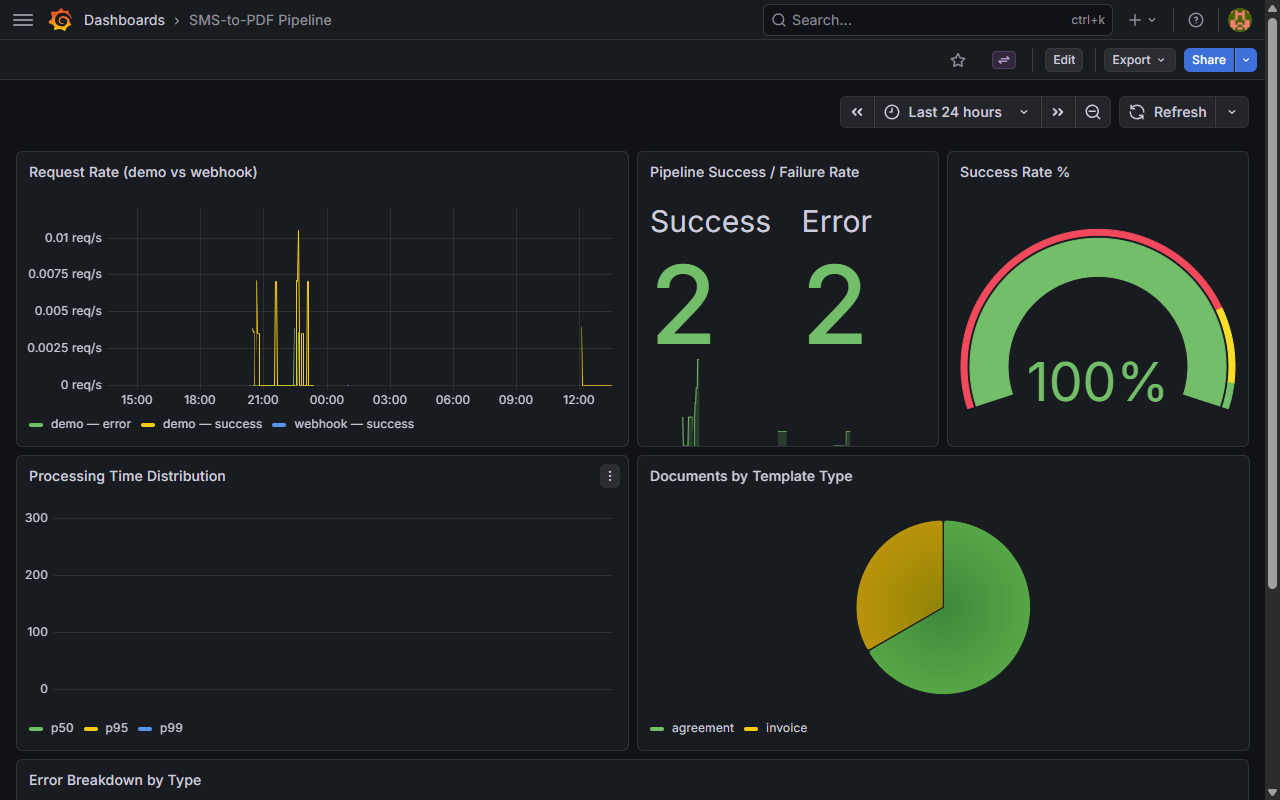
SMS-to-PDF exposes Prometheus metrics and Grafana dashboards show pipeline throughput, Claude API latency, and per-stage error rates. If the renderer sidecar falls behind, queue depth climbs and an alert fires before users notice anything is wrong.
Real inputs look nothing like test inputs
Prototypes work on five curated examples. Real users send misspellings, extra whitespace, missing fields, ambiguous phrasing, and data formatted in ways the prompt never saw. Production requires inputs to be sanitized before they reach the model (control characters stripped, whitespace normalized), the prompt to include examples of ambiguous or malformed input alongside the correct response, a fallback for cases where the model can’t confidently classify or extract, and edge-case coverage in test data for empty strings, Unicode characters, and unreasonably long inputs. And the test data has to include real user-submitted data at some point, not just sanitized examples, because the sanitized examples are exactly the cases the prototype already handles.
Structured output is not optional
If the model sometimes returns prose and sometimes returns JSON, the prompt is not enforcing structure and the system has a bug that just hasn’t surfaced under load yet. Production requires tool_use on Claude, function calling on OpenAI, or response_format: { "type": "json_object" }, combined with a strict JSON schema and validation against it. If the model returns invalid JSON, log it, retry with the schema repeated in the prompt, and if the retry fails, reject the request as unparsable. Prompts should be versioned and you should know which version is in production at any given moment.
Restart has to be survivable
Prototypes lose in-progress work when the service restarts. Production requires durable queues — Redis, RabbitMQ, a database — where work is written before processing starts, workers pull from the queue, process, and then acknowledge completion only when they’re done. If a worker crashes mid-request, the work goes back in the queue automatically and another worker picks it up. Queue depth and age have to be monitored, and you should have tested the restart path under load at least once before calling the system production-ready.
Troubleshooting the usual failures
“It works in testing but fails unpredictably in production.” The test data doesn’t represent real input variability — real users send misspellings and abbreviations and mixed case and extra punctuation, and the prompt was tuned on clean examples. Add structured output enforcement, include examples of malformed or ambiguous input in the prompt with the correct response, test with a hundred real samples rather than five curated ones, and log every model input and output for a week and then review the failures.
“It worked fine for a week and then started timing out.” Either the LLM API latency increased, the input size grew, a downstream service slowed down, or the queue is unbounded and finally caught up with you. Set explicit timeouts on every external call, monitor p50/p95/p99 latency with alerts, add queue depth and processing lag metrics, reject new work with a 503 when the queue exceeds a threshold, and profile the full request lifecycle to find the actual bottleneck instead of guessing.
“The model returns inconsistent outputs for the same input.” Temperature is above zero without a schema constraint, the instructions are ambiguous, or the few-shot examples in the prompt disagree with each other. Set temperature: 0 if deterministic output is required, enforce structured output with a strict schema, replace “extract relevant fields” with explicit schemas that name exactly the keys required, and check that the few-shot examples show a consistent format.
“The API provider changed something and now it breaks.” You pinned to latest instead of a specific model snapshot, or you had no integration tests running against the live API. Pin to an explicit model version, run daily integration tests against the live API, subscribe to provider changelogs, and stage any version change before flipping production.
“The error rate spiked and I don’t know what broke.” Insufficient logging. Log the full request context including input hash, user ID, timestamp, model version, and prompt version, add per-stage error counters so you can tell whether extraction, validation, or rendering was the thing that failed, include the request ID in every log line and return it in error responses, and store failed requests in a separate table so you can review them without trawling logs.
“The system can’t keep up with load.” Synchronous LLM calls block the worker, there’s no parallelism, and there’s no backpressure on ingestion. Use async workers to parallelize model calls, run multiple worker processes, reject new requests when queue depth exceeds a threshold, and add rate limiting at the entry point so the system can’t accept more than it can process.
“Costs are higher than expected.” The prompt is longer than it needs to be, there’s no caching for identical requests, retries are sending the full prompt again instead of just the failed portion, and nobody is tracking cost per request. Shorten the system prompt, cache responses for identical inputs keyed on a hash of the input plus prompt version, track cost per request in logs and metrics, and set a budget alert with a rate limit when it’s exceeded.
When it is time to get help
You probably need a production readiness review if the system works in development but you don’t know what will break at scale, if you have observability gaps where you can’t answer “what failed” without SSH-ing into the server, if failures currently require manual intervention to recover, or if you don’t know the cost per request or the maximum throughput the system can handle. That’s a specific kind of engagement and it has a specific deliverable — a written assessment covering where the AI is doing too much, which failure modes are unhandled, what observability is missing, and where the system will break under load — and the output is a prioritized list of fixes, not an open-ended advisory relationship.
If your prototype needs to run unsupervised in production and you want an outside pair of eyes on it before it does, the contact is contact@bogdan-ivanov.ro. Send the repository or a description of what the system does, and I’ll confirm whether a review makes sense and what the scope would look like.
Newsletter
Email updates
I write about building production AI systems with verifiable output through software engineering practices. One email when I publish, nothing else.
Thank you — you'll hear from me when the next post goes up.
Something went wrong. Please try again or email contact@bogdan-ivanov.ro directly.